Our event pipeline ingests roughly a billion events every single hour. Tens of Billions per day. A continuous firehose of user actions feeding into ClickHouse, where they have to be searchable in real time for segments, cohorts, funnels, and every analytics chart on the platform.
At that volume, every design choice you made years ago shows up - as a number on the storage bill, or as a number on the query latency chart. And one design choice from the early days was quietly costing us both.
So when a design decision from the early days started pushing query latency in the wrong direction, we couldn’t just live with it.
How we used to do it
The original schema looked sensible. Six neat columns, roughly:
eventsTable
ProductID, UserRefID, EventName, Source, Time
Properties → String (one big JSON blob per row)…with the usual MergeTree boilerplate around it - partitioned by day, sorted by (ProductID, EventName, UserRefID, Time), 91-day TTL. The cleverness - and, eventually, the curse - sat in that one Properties column. It was a single JSON string. Every event’s user-defined payload, whatever the SDK threw at us, got stringified and stuffed in.
A track("purchase", { amount: 1299, currency: "INR", item.sku: "X-1" }) became one row, and Properties became one little string: '{"amount":1299,"currency":"INR","item.sku":"X-1"}'. Simple. Universal. Worked the same way for every product, every event, every property.
For a long time, this was fine.
Why it stopped being fine
When you’re processing a billion events an hour, a JSON-blob design starts showing up in three different places at once.
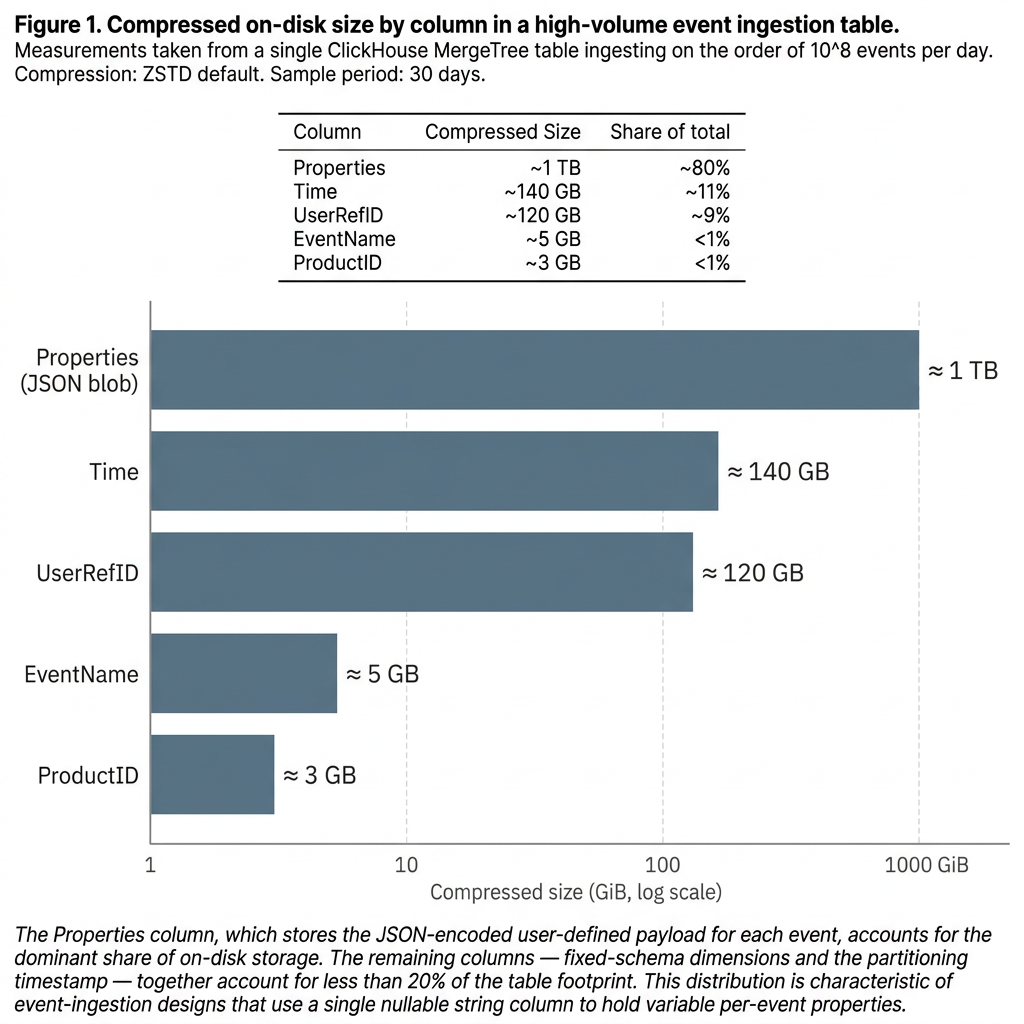
1. One column ate everything else
Here’s what was actually on disk:
| Column | Compressed | Share of table |
|---|---|---|
| Properties | ~10 TB | ~80% of everything |
| Time | ~1.4 TB | ~11% |
| UserRefID | ~1.20 TB | ~9% |
| EventName, ProductID, Source | A few GB combined | <1% |
Properties wasn’t just the biggest column - it was almost ten times bigger than the next one. Every byte we paid for, every disk page we read, was overwhelmingly that JSON blob. Storage cost was dominated by it. IO was dominated by it. Compaction was dominated by it.
2. Every property filter was expensive
A typical segment query looks like this:
WHERE EventName = 'purchase'
AND toFloat64OrZero(JSONExtractString(Properties, 'amount')) > 1000
AND JSONExtractString(Properties, 'country') = 'IN'Three quiet disasters in that query, none of which a column store can fix for you:
- No skipping. ClickHouse’s sparse indexes and granule pruning work on raw column values, not on the output of a function call. The moment you wrap
PropertiesinJSONExtractString, all the smart skipping logic is blindfolded. Every granule that survivesEventName = 'purchase'gets fully read. - No partial reads. Want one property? Doesn’t matter. The whole JSON string for that row gets pulled off disk anyway, because the entire blob is one column from ClickHouse’s perspective.
- Parsing, over and over. Each
JSONExtract*call re-parses the string from scratch. Three property predicates means three JSON parses per row. For tens of millions of rows. Per query.
The average payload was only ~550 bytes. The cost wasn’t bytes per row - it was that we’d quietly turned a column-oriented database into a row-store-with-extra-steps for the part of the data customers actually filter on.
3. Compression was working against us
Here’s the irony. The individual properties inside each payload were a column store’s dream. country has maybe 250 distinct values worldwide. currency has fewer than ten. item.sku is bounded by catalog size. A column-oriented store should crush these - dictionary encode them, reduce them to almost nothing on disk.
But ClickHouse couldn’t see any of that. From its perspective there was just one column called Properties, full of strings that as whole documents were almost always unique even though the values inside were wildly repetitive. We were paying the price of a row-store layout inside a column-store engine. The worst of both worlds.
Why we couldn’t just live with it
Two reasons. Both got worse with scale.
Storage. That ~10 TB Properties column was the single biggest line item on the storage side. A billion events an hour meant that number was still growing - fast. Throwing more disk at it was a treadmill, not a fix.
Latency. Property filters that ran in milliseconds at 10M rows ran in multiple seconds at 500M rows. Every dashboard chart, every cohort computation, every segment evaluation paid that tax. The bigger the table got, the worse the slowdown. The growth curve and the slowdown curve were the same curve, just plotted on different axes.
We didn’t need to replace ClickHouse. ClickHouse was great. We needed to stop using it the way you’d use Postgres. We needed to start using it the way a column store wants to be used.
What we wanted
We wrote the requirements down before touching anything:
- Property filters should be real column predicates, not function calls.
- Each property should get its own compression context so the column store can do its job.
- Schema flexibility has to survive. Products define their own events - thousands of them - each with its own evolving property set. Adding a new property at the SDK should not require a database migration.
- Drop-in for the pipeline. Same Kafka topic, same materialized view, same partitioning, same sort key, same TTL.
That last constraint is sneaky. “Schemaless” sounds like a property of the data. It’s actually a property of the contract: the SDK can add new properties at any time without telling us. Somewhere along the way we’d quietly conflated “schemaless contract” with “store JSON,” and that was the part we wanted to undo. The contract had to stay. The implementation could change.
What we tried, and what each thing taught us
We loaded the same one-hour event sample (a few million rows) into a series of candidate table designs and measured everything - disk size, compression, query latency, CPU.
Attempt 1: Just compress the JSON harder
The laziest possible fix: keep the JSON column, throw ZSTD at it, mark the dimension columns as LowCardinality. That’s it.
The numbers were genuinely impressive. The table dropped from ~900 MB to ~400 MB - more than half. Query CPU dropped almost 5x. Data read off disk dropped nearly an order of magnitude.
And yet this wasn’t the answer. Why? Because every one of those queries was still going through JSONExtractString. We’d compressed the symptom - fewer bytes off disk - but the parser cost was still there, the data-skipping indexes were still blind, and we’d locked ourselves into a world where every dashboard chart still parsed JSON on every refresh. We’d made the problem cheaper, not gone.
This was the “winning on the scoreboard, losing on principle” option.
Attempt 2: ClickHouse’s native JSON / Object type
ClickHouse has a newer JSON column type that introspects documents and automatically stores each unique key path as its own subcolumn. On paper it solves everything: real columns, real compression contexts, real data-skipping - no JSON parsing at query time.
In practice, there’s a hard architectural limit that makes this a poor fit for multi-tenant event stores.
The JSON type has a parameter called max_dynamic_paths (default: 1,024) that controls how many unique key paths get promoted to dedicated subcolumns. Paths within this limit behave like first-class columns - fast, skippable, independently compressed. But once the number of unique paths exceeds the limit, every additional path gets demoted into a single shared data structure - essentially a Map(String, String) blob underneath. Reading any overflow path means scanning this entire shared structure row by row, which is exactly the kind of per-row work we were trying to escape.
You can raise max_dynamic_paths, but ClickHouse’s own documentation recommends keeping it under 10,000. Push higher, and you start paying in other ways: each subcolumn becomes its own file on disk (or object in S3), so tens of thousands of subcolumns means tens of thousands of file descriptors, ballooning memory during inserts and merges, and slower compaction cycles.
Here’s the problem specific to our setup: we store events for thousands of products (tenants) and tens of thousands of event types in the same table. Every product defines its own properties - amount, currency, plan_name, screen_id, whatever the SDK sends. Across all products and all event types, the total number of unique property keys in a single table easily reaches ~100,000. With max_dynamic_paths capped at a recommended maximum of 10,000, the overwhelming majority of paths - 90% or more - would spill into shared data. We’d be right back to scanning a blob, just a differently shaped blob.
The positional-column approach sidesteps this entirely. The 100 PropN slots are scoped per (ProductID, EventName) pair through the external mapping. Product A’s amount claims Prop0; Product B’s completely unrelated screen_name also claims Prop0 - they never collide because the mapping is per-event. ClickHouse always sees exactly 100 columns, regardless of how many products or event types exist. No subcolumn explosion, no shared-data overflow, no file-descriptor pressure. The column count is fixed by design.
Attempt 3: Map(String, String) or Nested
These look like the right answer. A map column feels like it should give you “schemaless but typed.” Under the hood, though, a Map is stored as parallel key/value arrays. Filtering on Properties['country'] still has to walk every key in every row to find the one called country. Better than parsing JSON, but it’s still doing a per-row scan instead of a real column predicate. Same shape of problem, dressed up nicer.
Attempt 4: One table per event
5,000 events x N products x M Kafka topics x M materialized views. We did this math once, looked at each other, and moved on.
Attempt 5: Positional columns - the winner
This is the one we shipped. Replace Properties with 100 nullable string columns named Prop0 through Prop99. The first time country appears on a given event, it claims slot Prop2. From then on, country is Prop2 for that event, forever. The mapping from human-readable property names to slot numbers lives outside ClickHouse, in MongoDB.
In a one-hour sample, this approach finished at about ~430 MB - half the original, and within striking distance of the squeeze-the-JSON option. But unlike compressing JSON, this design actually solved the underlying problem: ClickHouse now sees a hundred real columns, each with its own values, its own compression context, its own indexes. The blob is gone.
How positional columns actually work
The shipped schema is satisfyingly boring:
userEventsTable
ProductID, UserRefID, EventName, Source, Time
Prop0, Prop1, Prop2, ..., Prop99 (one column per property slot)Same engine, same partitioning, same sort key, same TTL as before - the plumbing didn’t change. What changed was the shape of the table: one giant Properties blob became a hundred independent string columns, each with its own compression codec, each treated like a first-class column by ClickHouse. We also flipped a few small dials while we were at it:
- Every
PropNgets its ownZSTDcompression context.countrynow sees ~250 distinct strings,currencysees a handful, and dictionary compression finally has something to chew on. ProductIDandSourcebecomeLowCardinalitystrings - turned into dictionary IDs on disk and in memory. Faster equality checks, smaller marks.Timegets delta encoding. Within a sorted block, time is nearly monotonic, and delta encoding shrinks near-monotonic integers ferociously.
The schemaless half lives in MongoDB, on the events document:
{
"productId": "...",
"name": "purchase",
"propCounter": 7,
"propertyMapping": {
"amount": { "type": ["Float64"], "column": "Prop0" },
"currency": { "type": ["String"], "column": "Prop1" },
"country": { "type": ["String"], "column": "Prop2" }
}
}Write path. An incoming event gets flattened to dot-paths, each property looked up in propertyMapping, and the value dropped into the right PropN. A property we’ve never seen on (productId, eventName) atomically claims the next free slot, then the write proceeds. No DDL, no coordination, no schema migrations.
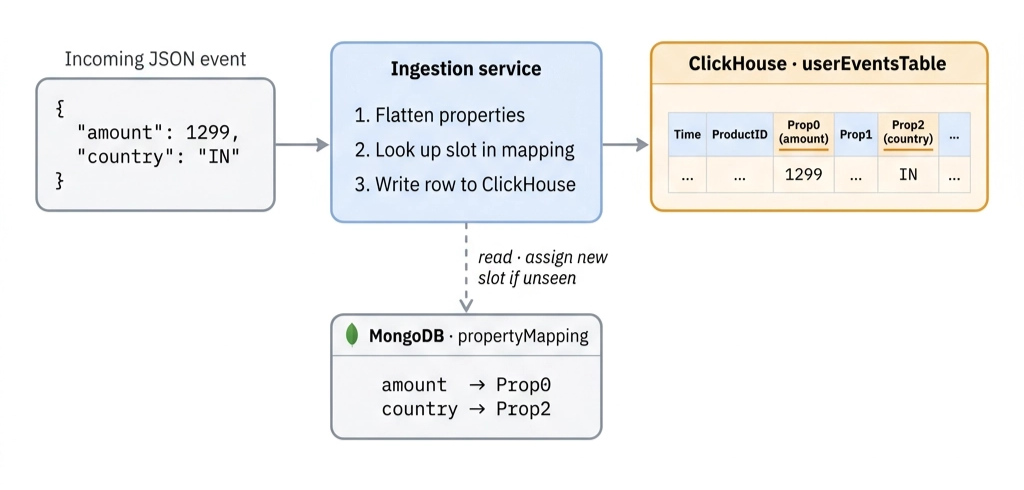
Read path. A query builder takes the logical filter country = 'IN', looks up the event’s mapping, and rewrites it to Prop2 = 'IN' before sending it to ClickHouse. Type info flows through too, so numeric comparisons coerce correctly. The SQL ClickHouse actually sees is what we’d always wanted to be able to write:
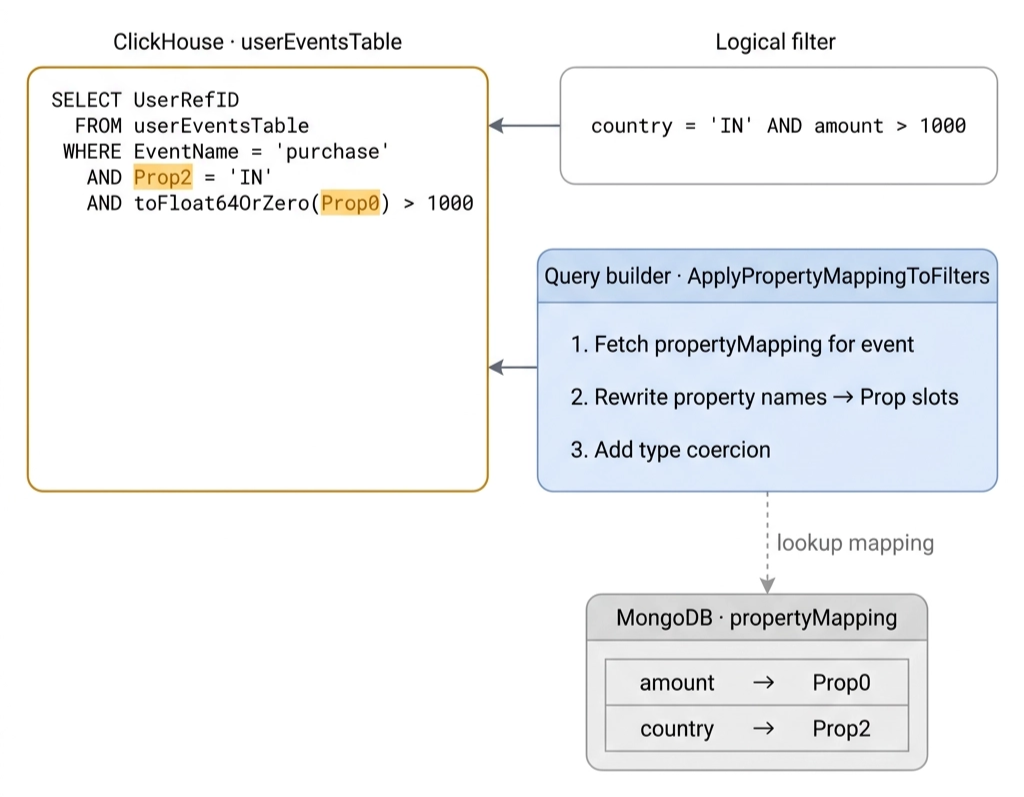
SELECT UserRefID FROM userEventsTable
WHERE EventName = 'purchase'
AND ProductID = '<id>'
AND Prop2 = 'IN'
GROUP BY UserRefID
HAVING SUM(toFloat64OrZero(Prop0)) > 1000The Mongo lookup that replaced a per-row JSON parse? It’s a single map lookup per query, served from an in-process cache with a two-minute TTL. The work that used to happen tens of millions of times per query now happens once.
What we learned
“Schemaless” is a requirement, not an implementation. The SDK contract - properties show up without warning - was the real constraint. Storing JSON was just one way to satisfy it. A thin layer of indirection (the name-to-slot mapping) lets you keep the contract and recover the column store at the same time.
Compression isn’t the same as efficiency. The “just compress the JSON” route had the best raw compression numbers of anything we tested. It still wasn’t the right answer, because we were optimizing for bytes on disk instead of what ClickHouse can do with those bytes. The query plan matters more than the file size.
A column store can only help if you give it columns. Every ClickHouse guide tells you this. We weren’t disagreeing - we just hadn’t given it any. The moment we did, all the goodies turned on by themselves: data-skipping indexes, dictionary encoding, per-column compression contexts. We didn’t have to do anything clever. We just had to stop hiding the data inside a string.
Visibility unlocks the next round of wins. With JSON, “how much disk is country using?” wasn’t even a question we could answer. With positional columns, system.parts_columns tells you exactly. That visibility is what makes per-property codec tuning, per-property TTLs, and per-property materialized aggregations possible at all.
What we got
Numbers, with all the decimal points rounded off because at this scale decimal points are a lie:
Storage. The biggest column in the database went from nearly a terabyte of JSON to a layout where the same data spreads across 100 properly-compressed columns. On a like-for-like one-hour sample, table size dropped by more than half - from ~900 MB to ~430 MB.
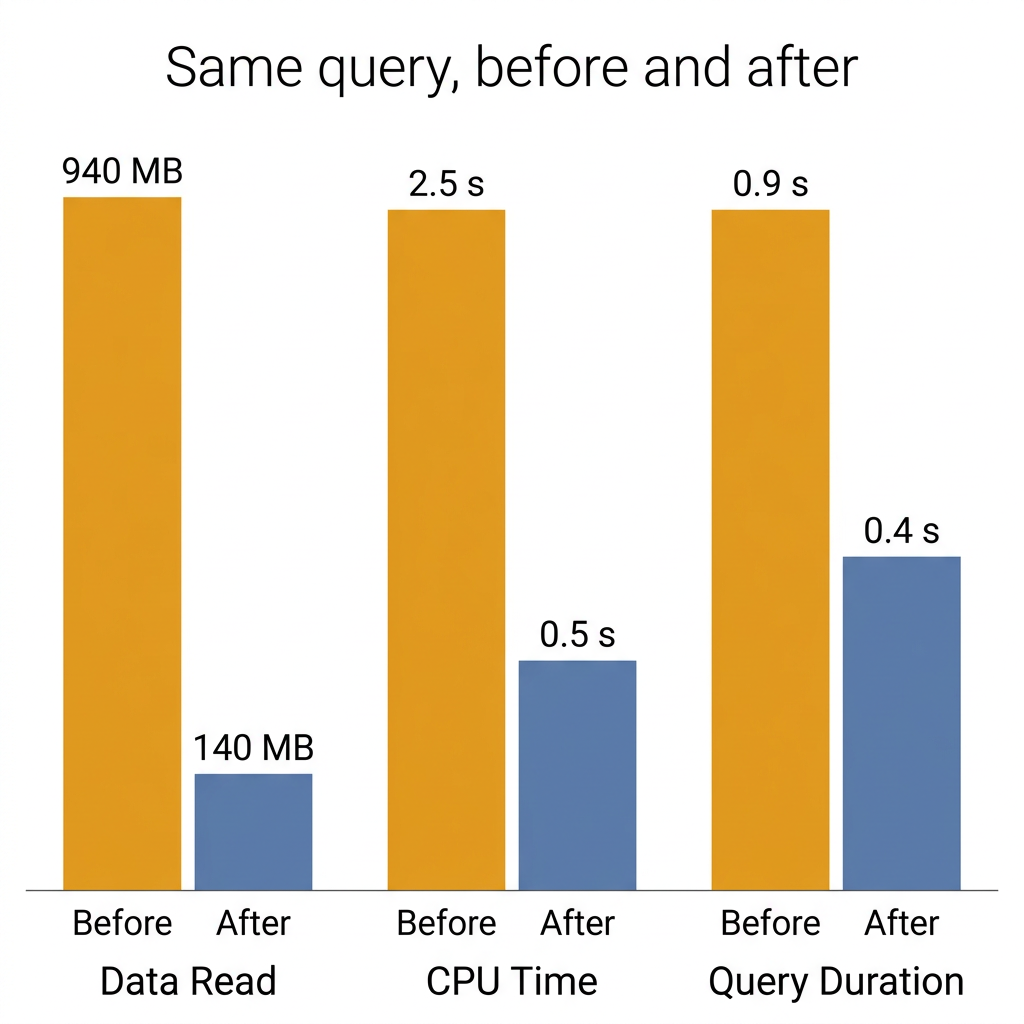
Query performance, on the same property-filter query:
| Before | After | Improvement | |
|---|---|---|---|
| Data read off disk | ~940 MB | ~140 MB | nearly 7x less |
| CPU time | ~2.5 seconds | ~0.5 seconds | nearly 5x less |
| Query duration | ~0.9 seconds | ~0.4 seconds | more than 2x faster |
Operational headroom. We can now read per-property disk usage straight out of system tables. We can tune codecs per column without touching anything else. We can set different TTLs for different properties if we want to. We can build materialized aggregations (SUM(amount), AVG(duration)) that read a single column instead of re-parsing JSON for every dashboard refresh. None of those were possible before. Not because they were forbidden - because ClickHouse’s Properties column was, from its point of view, a single string.
The migration is done. The old table is dropped. The new one is serving every event query on the platform.
If there’s a general lesson hiding in here, it’s this: when you build on a column store, the most useful question to ask about your schema is “what does the database actually see?” If the answer is “one column that contains everything,” it doesn’t matter how clever the compression is, or how well-chosen the sort key is, or how thoughtfully the partitions are laid out. The column store is doing nothing for you.
We gave it columns. It did the rest.