
.jpg)
Summary & Use Case
We needed a time-based task scheduler capable of reliably executing large volumes of work at precise times. At steady state, our system manages millions of tasks, each with a scheduled execution timestamp, a payload, and a lifecycle state (pending, processing, disabled, done).
The real challenge wasn’t just volume; it was bursts. A large fraction of tasks often become due at the exact same timestamp. Our scheduler needed to:
- Identify due tasks instantly.
- Enqueue them with minimal delay (jitter).
- Allow tasks to be safely disabled or canceled at any time.
- Scale horizontally without complex coordination or double execution.
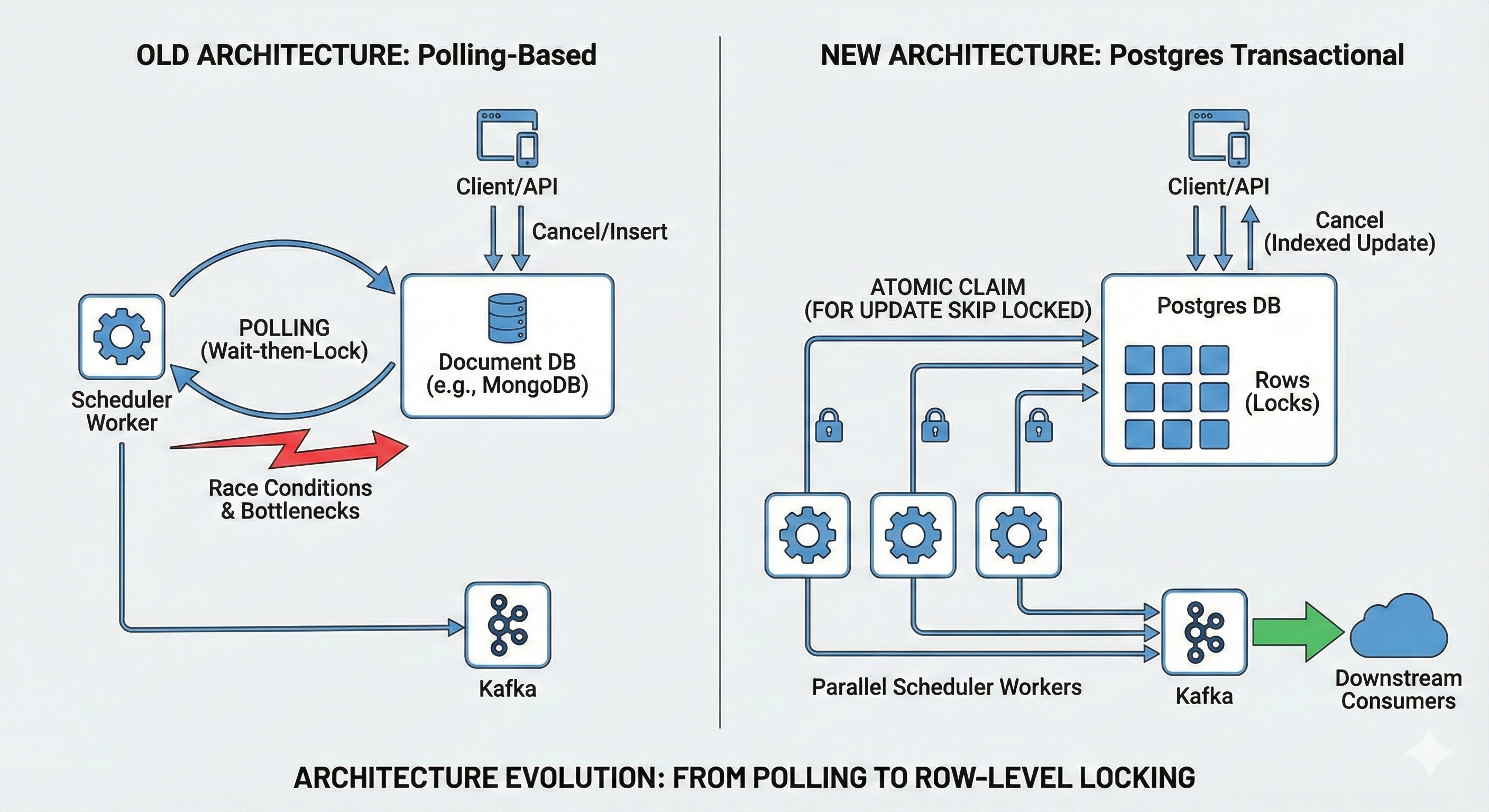
This post explains why our initial polling-based scheduler hit a scaling wall and how we migrated to a Postgres scheduler built on transactional row-level locking to solve it.
The Problem: Why Polling Failed at Scale
At a high level, a scheduler repeatedly performs two operations: Claim (find tasks where scheduled_time <= now) and Dispatch (send to Kafka).
Our original design used a document store (like MongoDB) and a simple polling loop.The Old Logic:
while true: # Find tasks that are pending and due tasks = db.find(status = 'PENDING' AND processing_timestamp <= now) for task in tasks: publish_to_kafka(task)Where It Failed
While simple to implement, this approach crumbled as volume increased:
- Single-Consumer Bottleneck: A single scheduler instance became the throughput ceiling.
- Uneven Latency: Large batches delayed unrelated tasks, causing high jitter.
- Race Conditions: Disabling tasks safely required complex coordination logic to ensure a task wasn’t executed while being cancelled.
- No Safe Parallelism: Adding more scheduler instances risked double execution (two workers picking up the same task).
The Solution: Postgres & Row-Level Locking
We redesigned the system around a single core idea: Claim work and transition state in a single database transaction.
We moved to Postgres to leverage FOR UPDATE SKIP LOCKED. This feature allows multiple workers to try to lock rows simultaneously; if a row is locked by Worker A, Worker B simply skips it and moves to the next one. This eliminates the need for leader election or external coordination.
1. The Data Model
We simplified the schema to support high-performance indexing:
CREATE TABLE triggers ( id BIGSERIAL PRIMARY KEY, type TEXT NOT NULL, key TEXT NOT NULL, status TEXT NOT NULL, -- PENDING / PROCESSING / DISABLED / DONE processing_timestamp BIGINT NOT NULL, data JSONB NOT NULL ); -- Index for claiming work CREATE INDEX idx_triggers_due ON triggers (type, processing_timestamp, status); -- Index for cancelling work CREATE INDEX idx_triggers_disable ON triggers (type, key, status);2. The New Scheduler Loop
Each scheduler worker now runs a tight loop that claims a batch of work atomically:“
BEGIN; WITH selected AS ( SELECT id FROM triggers WHERE type = 'TARGET_TYPE' AND status = 'PENDING' AND processing_timestamp <= now_ms() FOR UPDATE SKIP LOCKED LIMIT 1000 ) UPDATE triggersSET status = 'PROCESSING' WHERE id IN (SELECT id FROM selected) RETURNING id; COMMIT;Why This Works:
- FOR UPDATE: Locks the rows so no other worker can touch them.
- SKIP LOCKED: Tells other workers not to wait for these locks but to find other available rows.
- Atomic Transition: The status update happens in the same transaction as the read.
Once the transaction commits, the worker has exclusive ownership of those task IDs and publishes them to Kafka.
Key Design Decisions
**1. Database as the Concurrency Authority:**Instead of building “best-effort” deduplication in the application layer, we let the database enforce correctness. The “Lock + State Transition” is the atomic unit.
2. Horizontal Scale via Lock-Free Skipping:SKIP LOCKED allows linear scaling. If the queue grows, we simply spin up more worker instances. They naturally distribute the load without talking to each other.
**3. Cancellation is a First-Class Operation:**We optimized disable lookups with a dedicated index. This allows us to safely cancel triggers when user behavior changes without performing expensive table scans.
UPDATE triggers SET status = 'DISABLED' WHERE type = ? AND key = ? AND status = 'PENDING';“
4. Configurable Batch SizesWe treat LIMIT as a variable configuration. Smaller batches reduce lock contention, while larger batches maximize throughput during burst events.
Results
Migrating to the Postgres-based scheduler transformed our operational reliability:
- 10x Higher Throughput: Achieved with the same number of workers compared to the previous polling approach.
- Predictable Latency: Triggering delays dropped significantly, even when millions of tasks became due simultaneously.
- Linear Scalability: We can now scale up or down purely based on lag metrics without risking data correctness.
- Operational Simplicity: We no longer deal with complex race conditions or “zombie” tasks that were processed after being cancelled.
By leaning on Postgres primitives rather than application logic, we built a system that is faster, safer, and easier to maintain.